Performance Indicators
Metaheuristics.jl includes performance indicators to assess evolutionary optimization algorithms performance.
Available indicators:
Note that in Metaheuristics.jl, minimization is always assumed. Therefore these indicators have been developed for minimization problems.
Metaheuristics.PerformanceIndicators — Module
PerformanceIndicatorsThis module includes performance indicators to assess evolutionary multi-objective optimization algorithms.
gdGenerational Distance.igdInverted Generational Distance.gd_plusGenerational Distance plus.igd_plusInverted Generational Distance plus.coveringCovering indicator (C-metric).hypervolumeHypervolume indicator.
Example
julia> import Metaheuristics: PerformanceIndicators, TestProblems
julia> A = [ collect(1:3) collect(1:3) ]
3×2 Array{Int64,2}:
1 1
2 2
3 3
julia> B = A .- 1
3×2 Array{Int64,2}:
0 0
1 1
2 2
julia> PerformanceIndicators.gd(A, B)
0.47140452079103173
julia> f, bounds, front = TestProblems.get_problem(:ZDT1);
julia> front
F space
┌────────────────────────────────────────┐
1 │⠁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠈⠄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠈⢆⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠢⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠈⠢⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠉⠢⡄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
f_2 │⠀⠀⠀⠀⠀⠀⠀⠀⠈⠑⢤⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠲⢄⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠒⢤⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠙⠢⢄⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠑⠢⢄⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠈⠉⠢⠤⣀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│
│⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠉⠑⠢⢤⣀⠀⠀⠀⠀⠀│
0 │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠉⠒⠢⢄⣀│
└────────────────────────────────────────┘
0 1
f_1
julia> PerformanceIndicators.igd_plus(front, front)
0.0Pareto Front Utilities
Metaheuristics.pareto_front — Function
pareto_front(state::State)Returns the non-dominated solutions in state.population.
pareto_front(population::Array)Returns non-dominated solutions.
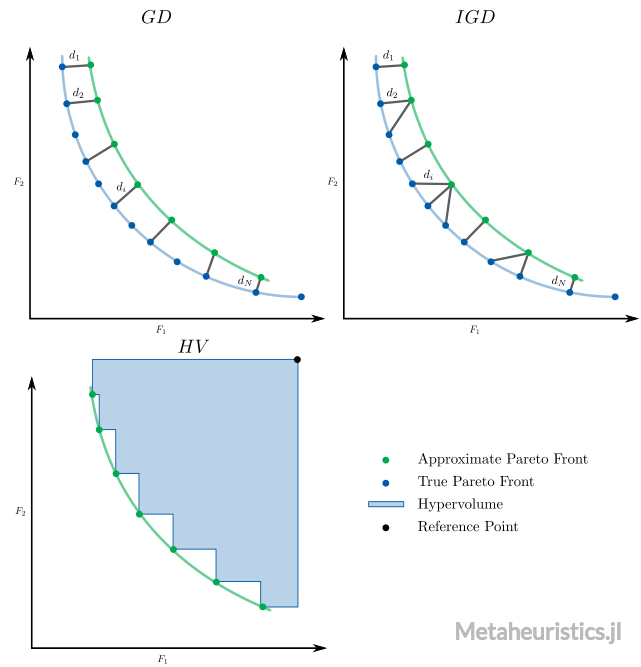
Generational Distance
These indicators are used to assess the accuracy of the Pareto front. They are defined as the average distance between a set of approximations of the Pareto front and a sample of the true Pareto front.
Metaheuristics.PerformanceIndicators.gd — Function
gd(front, true_pareto_front; p = 1)Returns the Generational Distance.
Parameters
front and true_pareto_front can be:
N×mmatrix whereNis the number of points andmis the number of objectives.StateArray{xFgh_indiv}(usuallyState.population)
Generational Distance Plus
Metaheuristics.PerformanceIndicators.gd_plus — Function
gd_plus(front, true_pareto_front; p = 1)Returns the Generational Distance Plus.
Parameters
front and true_pareto_front can be:
N×mmatrix whereNis the number of points andmis the number of objectives.StateArray{xFgh_indiv}(usuallyState.population)
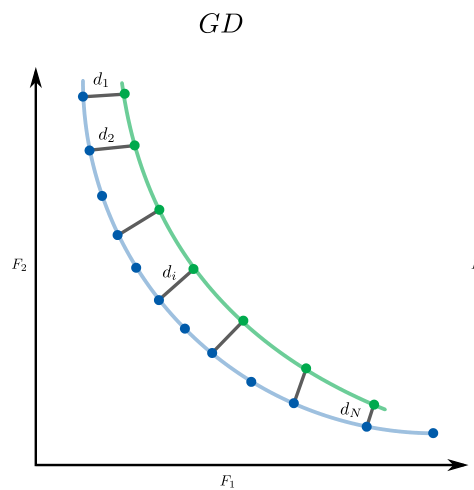
Inverted Generational Distance
Metaheuristics.PerformanceIndicators.igd — Function
igd(front, true_pareto_front; p = 1)Returns the Inverted Generational Distance.
Parameters
front and true_pareto_front can be:
N×mmatrix whereNis the number of points andmis the number of objectives.StateArray{xFgh_indiv}(usuallyState.population)
Inverted Generational Distance Plus
Metaheuristics.PerformanceIndicators.igd_plus — Function
igd_plus(front, true_pareto_front; p = 1)Returns the Inverted Generational Distance Plus.
Parameters
front and true_pareto_front can be:
N×mmatrix whereNis the number of points andmis the number of objectives.StateArray{xFgh_indiv}(usuallyState.population)
Spacing Indicator
Metaheuristics.PerformanceIndicators.spacing — Function
spacing(A)Computes the Schott spacing indicator. spacing(A) == 0 means that vectors in A are uniformly distributed.
Covering Indicator ($C$-metric)
Metaheuristics.PerformanceIndicators.covering — Function
covering(A, B)Computes the covering indicator (percentage of vectors in B that are dominated by vectors in A) from two sets with non-dominated solutions.
A and B with size (n, m) where n is number of samples and m is the vector dimension.
Note that covering(A, B) == 1 means that all solutions in B are dominated by those in A. Moreover, covering(A, B) != covering(B, A) in general.
If A::State and B::State, then computes covering(A.population, B.population) after ignoring dominated solutions in each set.
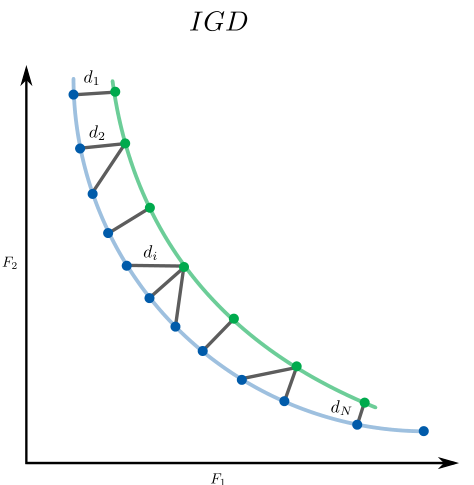
Hypervolume
This indicator is used to simultaneously assess the convergence and diversity of the Pareto front. It is defined as the volume between a set of approximations of the Pareto front and a reference point.
Metaheuristics.PerformanceIndicators.hypervolume — Function
hypervolume(front, reference_point)Computes the hypervolume indicator, i.e., volume between points in front and reference_point.
Note that each point in front must (weakly) dominates to reference_point. Also, front is a non-dominated set.
If front::State and reference_point::Vector, then computes hypervolume(front.population, reference_point) after ignoring solutions in front that do not dominate reference_point.
Examples
Computing hypervolume indicator from vectors in a Matrix
julia> import Metaheuristics.PerformanceIndicators: hypervolumejulia> f1 = collect(0:10); # objective 1julia> f2 = 10 .- collect(0:10); # objective 2julia> front = [ f1 f2 ]11×2 Matrix{Int64}: 0 10 1 9 2 8 3 7 4 6 5 5 6 4 7 3 8 2 9 1 10 0julia> reference_point = [11, 11]2-element Vector{Int64}: 11 11julia> hv = hypervolume(front, reference_point)66.0
Now, let's compute the hypervolume implementation in Julia from the result of NSGA3 when solving DTLZ2 test problem.
julia> using Metaheuristicsjulia> import Metaheuristics.PerformanceIndicators: hypervolumejulia> import Metaheuristics: TestProblems, get_non_dominated_solutionsjulia> f, bounds, true_front = TestProblems.DTLZ2();julia> result = optimize(f, bounds, NSGA3());julia> approx_front = get_non_dominated_solutions(result.population)⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀F space⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ ┌────────────────────────────────────────┐ 2 │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ f₂ │⡆⠠⠄⠠⢄⠀⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⡂⠀⠑⠀⠀⡂⠀⠑⡀⠂⠄⢀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠄⠀⠐⠀⠀⢀⠀⠀⠠⠀⠈⠠⠐⢀⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠄⠀⠈⠀⠂⡀⠀⠀⠠⠀⠀⠠⠀⠀⡀⠂⠄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠄⠀⠐⠀⠀⠀⠀⠀⡀⠀⠀⡀⠀⠀⡀⠀⡑⠂⠄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠄⠀⠂⠀⠀⠁⠀⠀⠀⠀⢀⠀⠀⢀⠀⠀⠀⠈⠐⠄⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ │⠄⠈⠂⠀⠈⠀⠀⠈⠀⠀⠀⠀⠀⠀⠀⠀⠁⠈⠐⠢⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ 0 │⡂⢐⠀⢀⠁⠀⡀⠁⠀⡈⠀⢀⠈⠀⡀⠁⡀⢁⠈⣑⡀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀│ └────────────────────────────────────────┘ ⠀0⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀2⠀ ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀f₁⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀julia> reference_point = nadir(result.population)3-element Vector{Float64}: 1.0236927213281788 1.0013222126143206 1.0009564451830488julia> hv = hypervolume(approx_front, reference_point)0.4371490373560277
$\Delta_p$ (Delta $p$)
This indicator computes the average Hausdorff distance between a set of approximations of the Pareto front and a sample of the true Pareto front.
Metaheuristics.PerformanceIndicators.deltap — Function
deltap(front, true_pareto_front; p = 1)
Δₚ(front, true_pareto_front; p = 1)Returns the averaged Hausdorff distance indicator aka Δₚ (Delta p).
"Δₚ" can be typed as \Delta<tab>\_p<tab>.
Parameters
front and true_pareto_front can be:
N×mmatrix whereNis the number of points andmis the number of objectives.Array{xFgh_indiv}(usuallyState.population)
$\varepsilon$-Indicator
Unary and binary $\varepsilon$-indicator (epsilon-indicator). Details in (Zitzler et al., 2003)
Metaheuristics.PerformanceIndicators.epsilon_indicator — Function
epsilon_indicator(A, B)Computes the ε-indicator for non-dominated sets A and B. It is assumed that all values in A and B are positive. If negative, the sets are translated to positive values.
Interpretation
epsilon_indicator(A, PF)is unary ifPFis the Pareto-optimal front.epsilon_indicator(A, B) == 1none is better than the other.epsilon_indicator(A, B) < 1means that A is better than B.epsilon_indicator(A, B) > 1means that B is better than A.- Values closer to 1 are preferable.
Examples
julia> A1 = [4 7;5 6;7 5; 8 4.0; 9 2];
julia> A2 = [4 7;5 6;7 5; 8 4.0];
julia> A3 = [6 8; 7 7;8 6; 9 5;10 4.0 ];
julia> PerformanceIndicators.epsilon_indicator(A1, A2)
1.0
julia> PerformanceIndicators.epsilon_indicator(A1, A3)
0.9
julia> f, bounds, pf = Metaheuristics.TestProblems.ZDT3();
julia> res = optimize(f, bounds, NSGA2());
julia> PerformanceIndicators.epsilon_indicator(res, pf)
1.00497701620997